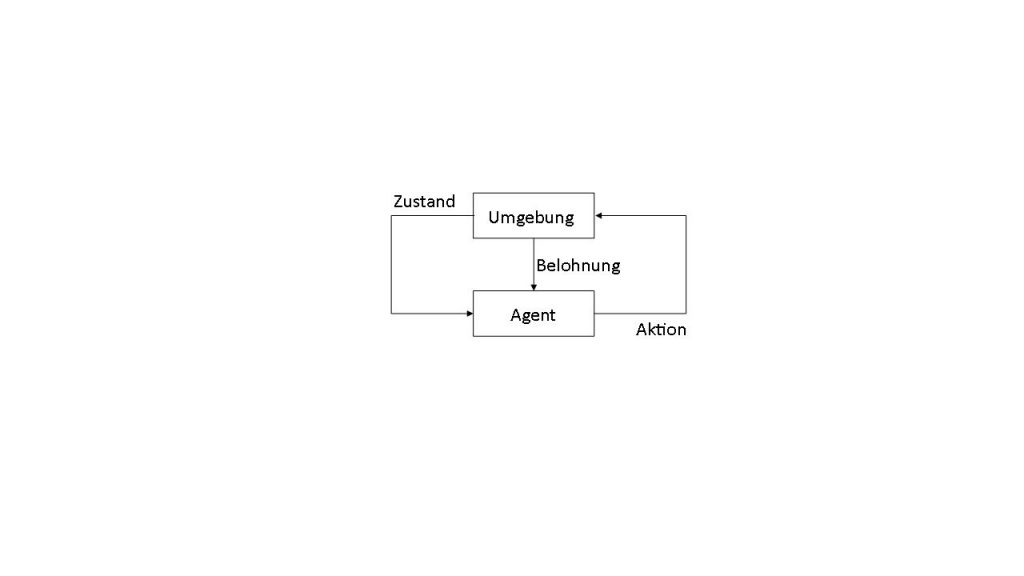
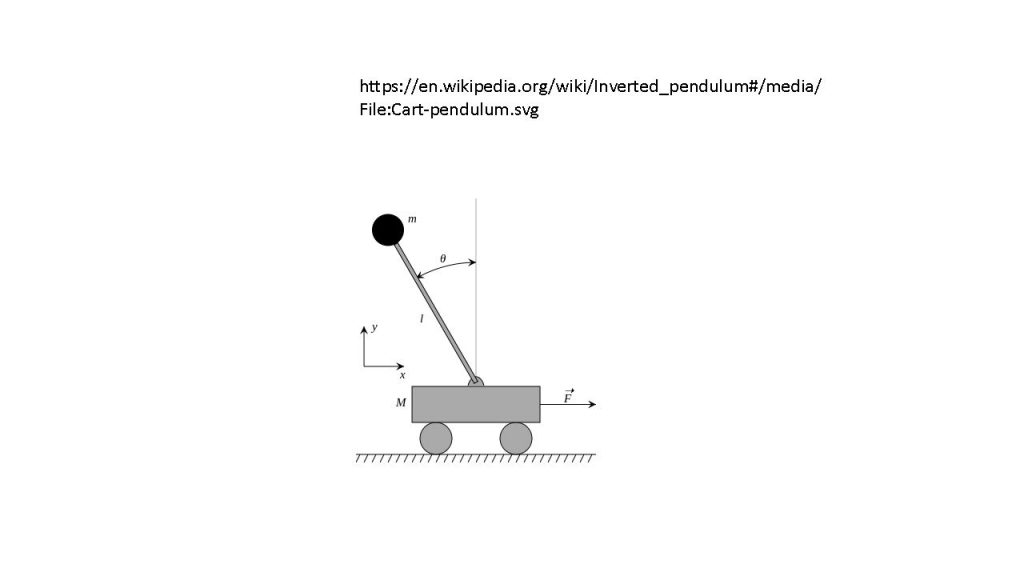
Das Ausprobieren erfolgt in den meisten Fällen mithilfe einer Simulation, bei der der Reinforcement Learning Agent eine vordefinierte Anzahl und Art an Aktionen durchführt und seine Belohnung sowie Änderungen in seiner Umgebung beobachtet. Simulationen als Umgebungen sind bei meisten Anwendungsfällen Voraussetzung für den Lernprozess. Bekannte Beispiele für Simulationsumgebungen sind Videospiele oder Simulationen von Brettspielen wie Schach oder Go, bei denen Reinforcement-Learning-Agenten eine möglichst hohe Punktzahl als Ziel (und auch als Belohnung) haben. Ein weiteres bekanntes Beispiel für eine Reinforcement-Learning-Umgebung, die näher an der Produktionstechnik liegt, ist die Simulation eines invertierten Pendels. Seine Dynamikgleichungen sind einfach und können in jeder Programmiersprache implementiert und simuliert werden. Für das bestärkende Lernen ist es dabei wichtig, zu entscheiden, welche Belohnung der Agent bekommt und wann. Beim Pendelbeispiel ist es relativ simpel: Der Agent wird belohnt wenn das Pendel oben steht und möglichst wenig Geschwindigkeit hat. Diese einfache Simulationsumgebung kann an die neuen Reinforcement-Learning-Algorithmen gekoppelt werden und eine Strategie, durch die das Pendel nach oben gehalten wird, kann erlernt werden. Reinforcement Learning kann aber auch Steuerungslogik für Produktionssysteme erlernen, falls das Produktionssystem als eine für das Lernen geeignete Simulation aufgebaut ist.
Benchmark und Schnittstelle
Um Benchmarking mehrerer Agenten in derselben Umgebung zu ermöglichen, wurde die Open-Source-Bibliothek OpenAI Gym entwickelt. Es bietet eine Sammlung von Umgebungen, von invertierten Pendeln bis hin zu Videospielen, die in der Programmiersprache Python entwickelt wurden. OpenAI Gym ist aber mehr als nur eine Sammlung von Umgebungen. Es definiert eine einheitliche Schnittstelle für alle Umgebungen und Implementierungen der neusten Lernmethoden. In der Praxis bedeutet das, dass man innerhalb weniger Minuten ohne Modellierungs- oder Schnittstellenentwicklungsaufwand eine Umgebung und eine Lernmethode herunterladen und den Lernprozess starten kann. Neue Umgebungen können hinzugefügt werden. Diese haben eine fest definierte Struktur (auch als Dateisystem, aber auch als Komponentenmodell) und müssen ein Umgebungsmodell beinhalten.
Modelle in der Steuerungstechnik
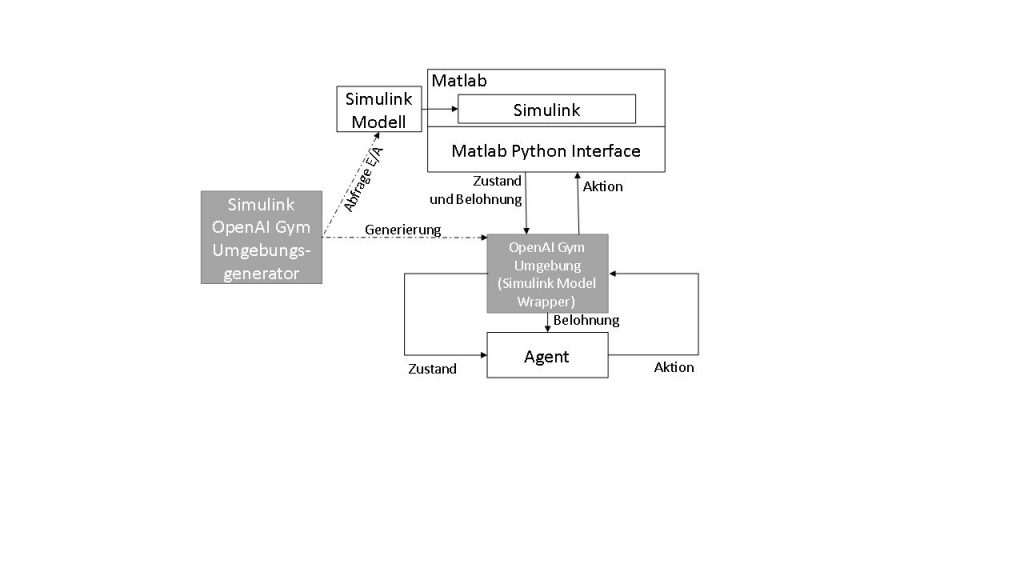
Modellierung in der Produktionstechnik ist aber weit entfernt von einfachen Python-Skripten. Existierende Modelle können die Realität mit der benötigten Genauigkeit abbilden. Sie werden in Simulationsumgebungen wie Matlab Simulink entwickelt. Manche werden als digitaler Zwilling der realen Maschine bezeichnet. Das Matlab Python Interface bietet eine Schnittstelle für die gesamte Entwicklungsumgebung nach Python und der Matlab/Simulink Coder bietet die Möglichkeit, für verschiedene Plattformen C/C++-Codes zu generieren und zu kompilieren (inklusive C/C++-Schnittstelle). Beide Optionen können verwendet werden, um einen Wrapper für die Simulation zu entwickeln, der nach der OpenAI-Gym-Struktur ausgelegt ist. Die Matlab-Schnittstellen und die OpenAI-Gym-Schnittstelle bieten aber für alle Simulationen dieselben Interaktionsmöglichkeiten. Dies erlaubt die automatisierte Generierung von einer Zwischenschicht, die von einer Seite als OpenAi-Gym-Umgebung erkannt wird und von der anderen Seite alle Informationen an die Matlab-Schnittstellen weiterleitet.
OpenAI Gym-Schnittstelle
OpenAI-Gym-Umgebungen sind in Python implementiert, können aber Aufrufe nach weiteren Komponenten beinhalten. Die Methoden (Funktionen), mit denen eine OpenAI-Gym-Umgebung implementiert werden soll, sind die Folgenden: