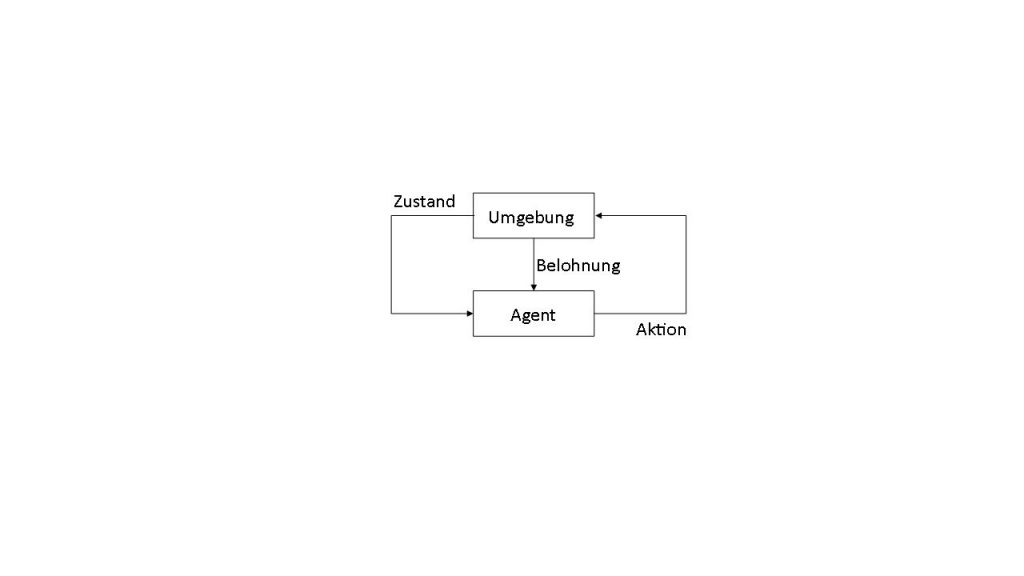
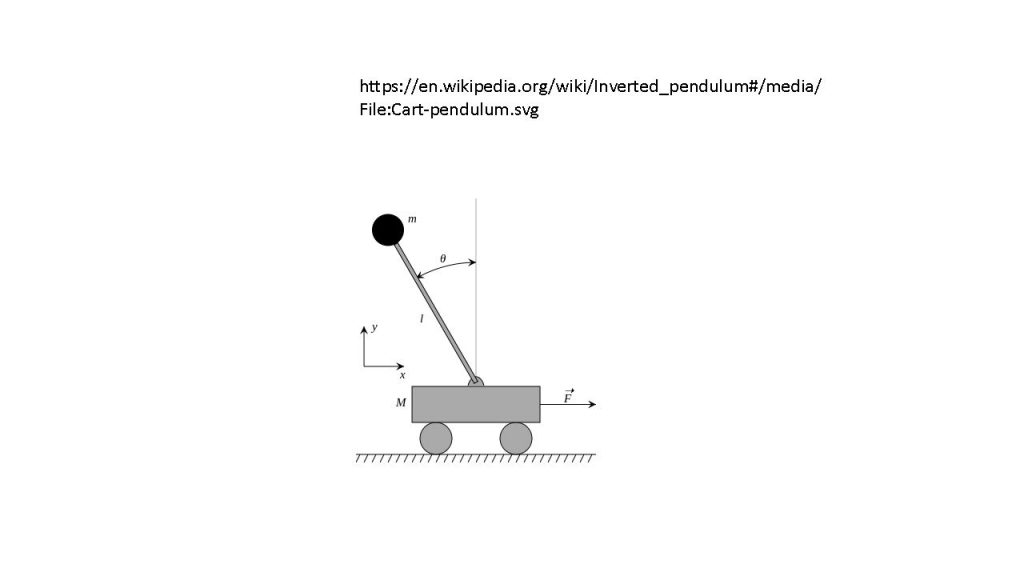
Das Ausprobieren erfolgt in den meisten Fällen mithilfe einer Simulation, bei der der Reinforcement Learning Agent eine vordefinierte Anzahl und Art an Aktionen durchführt und seine Belohnung sowie Änderungen in seiner Umgebung beobachtet. Simulationen als Umgebungen sind bei meisten Anwendungsfällen Voraussetzung für den Lernprozess. Bekannte Beispiele für Simulationsumgebungen sind Videospiele oder Simulationen von Brettspielen wie Schach oder Go, bei denen Reinforcement-Learning-Agenten eine möglichst hohe Punktzahl als Ziel (und auch als Belohnung) haben. Ein weiteres bekanntes Beispiel für eine Reinforcement-Learning-Umgebung, die näher an der Produktionstechnik liegt, ist die Simulation eines invertierten Pendels. Seine Dynamikgleichungen sind einfach und können in jeder Programmiersprache implementiert und simuliert werden. Für das bestärkende Lernen ist es dabei wichtig, zu entscheiden, welche Belohnung der Agent bekommt und wann. Beim Pendelbeispiel ist es relativ simpel: Der Agent wird belohnt wenn das Pendel oben steht und möglichst wenig Geschwindigkeit hat. Diese einfache Simulationsumgebung kann an die neuen Reinforcement-Learning-Algorithmen gekoppelt werden und eine Strategie, durch die das Pendel nach oben gehalten wird, kann erlernt werden. Reinforcement Learning kann aber auch Steuerungslogik für Produktionssysteme erlernen, falls das Produktionssystem als eine für das Lernen geeignete Simulation aufgebaut ist.
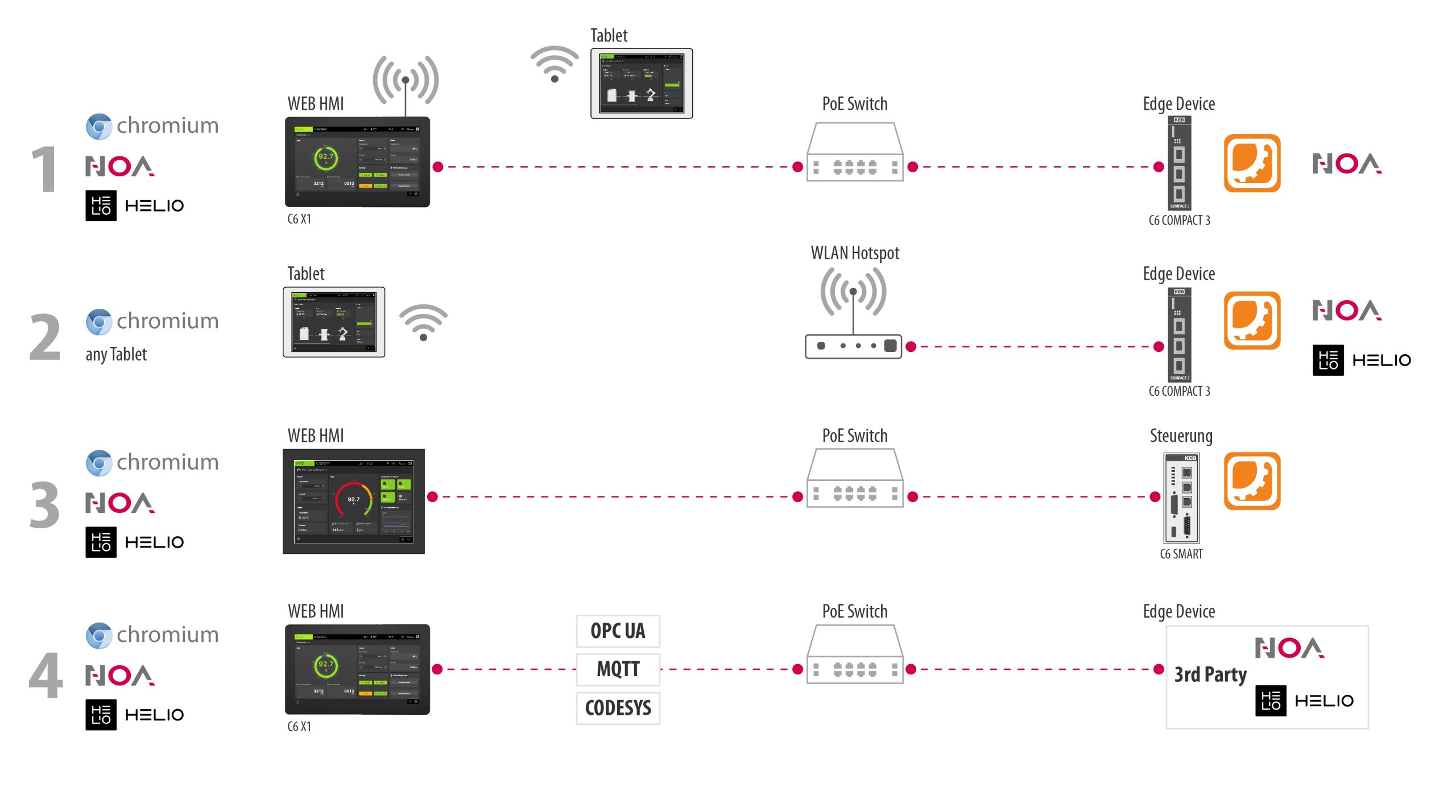
Benchmark und Schnittstelle
Um Benchmarking mehrerer Agenten in derselben Umgebung zu ermöglichen, wurde die Open-Source-Bibliothek OpenAI Gym entwickelt. Es bietet eine Sammlung von Umgebungen, von invertierten Pendeln bis hin zu Videospielen, die in der Programmiersprache Python entwickelt wurden. OpenAI Gym ist aber mehr als nur eine Sammlung von Umgebungen. Es definiert eine einheitliche Schnittstelle für alle Umgebungen und Implementierungen der neusten Lernmethoden. In der Praxis bedeutet das, dass man innerhalb weniger Minuten ohne Modellierungs- oder Schnittstellenentwicklungsaufwand eine Umgebung und eine Lernmethode herunterladen und den Lernprozess starten kann. Neue Umgebungen können hinzugefügt werden. Diese haben eine fest definierte Struktur (auch als Dateisystem, aber auch als Komponentenmodell) und müssen ein Umgebungsmodell beinhalten.
Modelle in der Steuerungstechnik
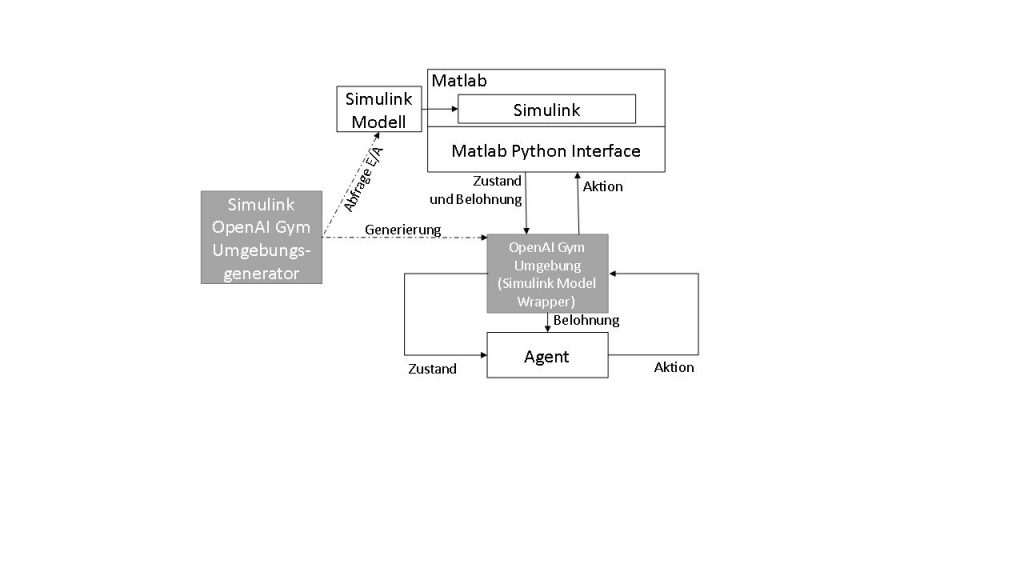
Modellierung in der Produktionstechnik ist aber weit entfernt von einfachen Python-Skripten. Existierende Modelle können die Realität mit der benötigten Genauigkeit abbilden. Sie werden in Simulationsumgebungen wie Matlab Simulink entwickelt. Manche werden als digitaler Zwilling der realen Maschine bezeichnet. Das Matlab Python Interface bietet eine Schnittstelle für die gesamte Entwicklungsumgebung nach Python und der Matlab/Simulink Coder bietet die Möglichkeit, für verschiedene Plattformen C/C++-Codes zu generieren und zu kompilieren (inklusive C/C++-Schnittstelle). Beide Optionen können verwendet werden, um einen Wrapper für die Simulation zu entwickeln, der nach der OpenAI-Gym-Struktur ausgelegt ist. Die Matlab-Schnittstellen und die OpenAI-Gym-Schnittstelle bieten aber für alle Simulationen dieselben Interaktionsmöglichkeiten. Dies erlaubt die automatisierte Generierung von einer Zwischenschicht, die von einer Seite als OpenAi-Gym-Umgebung erkannt wird und von der anderen Seite alle Informationen an die Matlab-Schnittstellen weiterleitet.
OpenAI Gym-Schnittstelle
OpenAI-Gym-Umgebungen sind in Python implementiert, können aber Aufrufe nach weiteren Komponenten beinhalten. Die Methoden (Funktionen), mit denen eine OpenAI-Gym-Umgebung implementiert werden soll, sind die Folgenden:
- init() – Hier werden die Parameter gesetzt, mit denen die Umgebung arbeitet, z.B. die Dimensionen der Ein- und Ausgänge.
- reset() – Wie der Name schon sagt, wird mit dieser Funktion die gesamte Simulation zurückgesetzt.
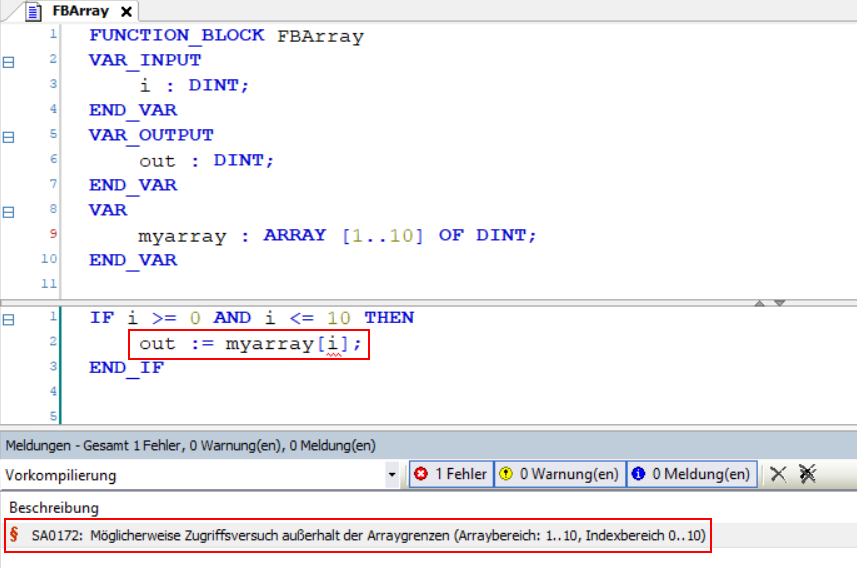
- step() – Diese Funktion wird aufgerufen, wenn ein Simulationsschritt ausgeführt werden soll.
- seed() – Diese Funktion wird für die Neuparametrisierung des Zufallsgenerators verwendet.
- render() – Diese Funktion erzeugt eine grafische Abbildung der Umgebung.
Von diesen Funktionen sind aber nur init(), step() und reset() für einen Lernprozess notwendig. Die anderen Funktionen müssen nicht verwendet werden. Eine Simulation wird unabhängig von ihrer Visualisierung (die render()-Funktion) durchgeführt. Wichtig sind noch die Eingangs- und Ausgangsvariablen für die Step-Funktion. Eingang ist die auszuführende Aktion und Ausgänge sind: der geänderte Zustand der Umgebung, die Belohnung und, falls das Problem eine endliche Zeithorizont hat, die Erreichung des Zielzustandes.
Dateistruktur mit Namen und Referenz
Eine selbstgeschriebene OpenAI-Gym-Umgebung muss, wie bereits erwähnt, eine gewisse Dateistruktur besitzen. Die sogenannte PIP-Package-Struktur beinhaltet eine Namens- und Referenzierungskonvention, die einfach zu generieren ist. Eine OpenAI-Gym-Umgebung, die eine Simulink-Simulation beinhaltet, soll innerhalb der Methoden mit Matlab über die Matlab Python Interface oder mit kompilierten Simulink-Modellen über deren Schnittstelle kommunizieren. So werden komplexe Simulink-Modelle zu OpenAI-Gym-Umgebungen. Ein OpenAI-Gym-Umgebungsgenerator soll die zur Verfügung stehenden Informationen aus dem Simulink-Modell auslesen und damit den Quellcode, basierend auf einem Template, generieren. Das Template besteht aus Python-Quellcode, bei dem an den Stellen, an denen Änderungen notwendig sind einfach erkennbare Platzhalter stehen, die mit aus den Simulink-Modell ausgelesenen Informationen befüllt werden. Der Generator entpackt die Simulink-Datei (.slx) und kann aus der resultierenden XML-Datei die wichtigen Informationen herauslesen. Dazu gehören die Ein- und Ausgänge (Inputs und Outputs) sowie die zusätzlich benötigten Informationen. Dies wird dann in der OpenAI-Gym-Dateistruktur abgespeichert und kann als gewöhnliche Umgebung verwendet werden.
- Eingänge: Die Agenten der RL-Algorithmen müssen bestimmte Aktionen ausführen können. Bei dem Beispiel eines invertierten Pendels wären die Aktionen das Hin- und Herfahren des unteren Wagens. Diese Aktionen werden vom Agenten an die Umgebung weitergegeben. Der Wrapper gibt diese Aktionen an Simulink weiter. Da die die Python-Interface die Simulink Input-Blöcke in der aktuellen Matlab-Version nicht mit Werte befüllen kann, werden diese temporär ersetzt.
- Ausgänge: Nachdem die Eingänge gesetzt wurden, simuliert das Modell nun einen Zeitschritt und die Output-Blöcke der Simulink-Simulation werden mit neuen Werte gesetzt. Dieser Output wird von dem Wrapper abgegriffen und wieder zurück an den RL-Algorithmus gesendet.
Zusätzlich benötigte Informationen: Ergänzend zu den Ein- und Ausgängen benötigt eine Umgebung die Belohnungsfunktion. Sie kann zusätzlich zum Modell im Simulink implementiert werden und die Belohnung wird vom Wrapper abgegriffen bzw. weitergeleitet.
Matlab-Python-Schnittstelle
Nachdem die wichtigen Informationen aus der XML-Datei entnommen wurden und der Umgebungs-Quellcode in Python generiert wurde, muss die Verbindung zwischen Python und Matlab erzeugt werden. Mit der Matlab Python Interface kann die Simulation gestartet, pausiert und fortgeführt werden. Bei einem Simulationsschritt ist es möglich, die (umgewandelten) Inputs zu schreiben und die Outputs zu lesen. In die aktuelle Matlab-Version einen Simulationsschritt zu integrieren ist nur durch Umwege (mit eingebautem Stop/Pause-Block) möglich.
Verwendung des Umgebungsgenerators
Um den Simulink-OpenAI-Gym-Umgebungsgenerator zu verwenden, muss die Generatorfunktion mit dem Pfad der Simulink-Datei ausgeführt werden. Danach erstellt der Generator die Python-Quellcodedateien und die Dateistruktur. Sobald dies abgeschlossen ist, ist die Umgebung durch die PIP-Anwendung als OpenAI-Gym-Umgebung registriert und verwendbar. Selbstverständlich muss Matlab installiert sein, um die Umgebung verwenden zu können. Dies hat auch den Vorteil, dass es im Gegensatz zur Verwendung von vorkompilierten Modellen einfache Experimente in der bekannten Simulink-Umgebung erlaubt.
Zusammenfassung und Ausblick
Durch den OpenAI-Gym-Generator ist es möglich, jedes Simulink-Modell ohne großen Aufwand in eine Reinforcement-Learning-Umgebung zu konvertieren und mit anderen zu teilen. Das führt zur Entstehung schneller und effizienter Lösungen. Damit bildet dieser Generator das Bindeglied zwischen den neusten Reinforcement-Learning-Methoden und den steuerungstechnischen Simulationen. Der Generator wird zurzeit mit vielversprechenden Ergebnissen am Institut für Steuerungstechnik der Werkzeugmaschinen und Fertigungseinrichtungen der Universität Stuttgart entwickelt.
SPS-MAGAZIN 9/2018: Ethernet TSN und Open Source
SPS-MAGAZIN 10/2018: Reinforcement Learning mit Simulink-Modellen
SPS-MAGAZIN 11/2018: Tool für die virtuelle Produktion
SPS-MAGAZIN 12/2018: Ausblick: Stuttgarter Innovationstage 2019
Stuttgarter Innovationstage 2019
Der revolutionäre Ansatz von Steuerungen aus der Cloud stand oft in Konflikt mit konservativen IT-Vorgaben und stellte daher Partner mit großen IT-Infrastrukturen vor organisatorische Hürden. Um einen engen Austausch über verschiedene Fachbereiche hinweg zu fördern, veranstaltet das Institut für Steuerungstechnik der Universität Stuttgart zum dritten Mal die ‚Stuttgarter Innovationstage – Steuerungstechnik aus der Cloud‘. Mit Vorträgen aus den Fachbereichen IT und klassischer Automatisierungstechnik können Teilnehmer am 12. und 13. Februar 2019 in Stuttgart den nächsten Schritt zum interdisziplinären Wissensaustausch machen.