Heutzutage kann zwar auf Echtzeitdaten von Sensoren und Steuerungen zugegriffen werden, allerdings werden diese bisher nicht in standardisierter Form durch Nutzung von digitalen Dienstleistungen (Services) verwendet. Ein Grund hierfür ist deren aufwändige Entwicklung und Integration, was der fehlenden Sammlung von Schnittstellen und Serviceplattformen zur Verwaltung und Auswertung von Informationen geschuldet ist. Erst wenn solche Schnittstellen und Architekturen existieren, können Geschäftsmodelle auf Basis der digitalen Dienstleistungen entwickelt und angeboten werden. An diesem Punkt setzt das BMBF-Forschungsprojekt ‚MultiCloud-basierte Dienstleistungen für die Produktion‘ an. Ziel ist eine Serviceplattform, die den Entwicklungs- und Integrationsaufwand von neuen Services verringert sowie deren kostengünstigen Betrieb und Nutzung ermöglicht. Dafür arbeiten im Rahmen des Projektes Serviceanbieter, Anwender und Forschungseinrichtungen zusammen.
Multicloud-basierte Dienstleistungsplattform
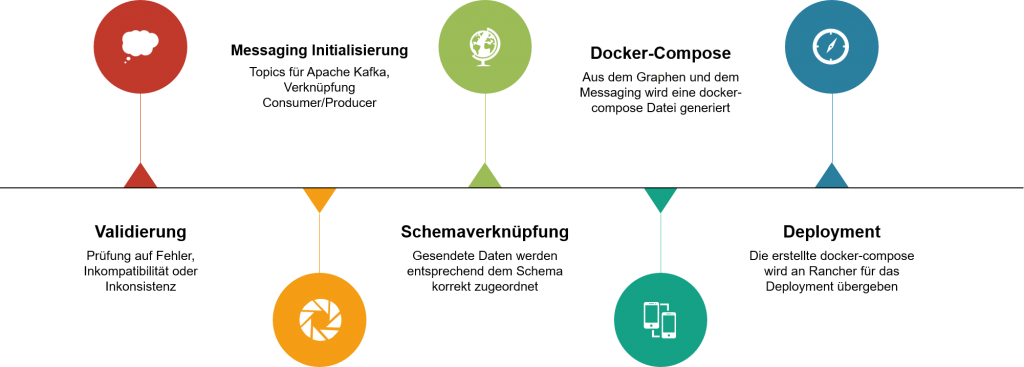
Als Basis zur Realisierung von Use Cases kommt die MultiCloud-basierte Serviceplattform des Projektes zum Einsatz. Dabei können Services über ein Web-UI ausgewählt, verknüpft und konfiguriert werden. Sie werden anschließend mithilfe von Containertechnologien (Docker) verpackt und auf einer oder mehreren hinterlegten Cloud-Instanzen deployt. Hierbei wird das Provisionieren der Cloud-Instanzen sowie das Management der einzelnen Container mithilfe des OpenSource-Systems Rancher realisiert. Damit die Services über Instanzgrenzen hinweg kommunizieren können, wird ein nachrichtenorientiertes System auf Basis der Publisher/Subscriber-Messaging-Lösung Apache Kafka verwendet. Die verwendeten Services können jederzeit ausgetauscht werden, ohne die Schnittstellen der anderen Services anpassen zu müssen. Durch die Kombination aus den genannten Technologien ist es möglich, die Vielfalt an Services hinsichtlich deren Anforderung an Dantemengen und Verfügbarkeit zu realisieren. Um bei neuen Services den Entwicklungs- und Integrationsaufwand gering und Betrieb bzw. Nutzung so kostengünstig wie möglich zu halten, werden verschiedene Werkzeuge bereitgestellt. Eines dieser Werkzeuge ist die im Projekt entwickelte Graph-Pipeline, die aus der vom Benutzer erstellten Servicekomposition einen Deployment-Plan generiert. Hierbei wird zunächst die Verknüpfung zwischen den Services validiert. Anschließend wird die Kommunikation über Kafka initialisiert. Dabei werden sogenannte Topics festgelegt, an diese die Services ihre Nachrichten übermitteln und lesen können. Damit ein Service die gesendete Nachricht auch verarbeiten kann, werden die Daten mit dem jeweiligen Schema des Services verknüpft. Dieser Schritt ermöglicht den Austausch und die Wiederverwendbarkeit in der Plattform, da im hinterlegten Schema alle benötigten Informationen für einen Datenaustausch enthalten sind. Nachdem die Konfiguration des Nachrichtenaustauschs erfolgt ist, werden die konfigurierten Services in einer Docker-Compose-Datei beschrieben. So lassen sich innerhalb einer Datei mehrere Container einstellen und ihre Beziehungen untereinander definieren. Abschließend wird die generierte Datei dazu verwendet, um mithilfe von Rancher die Services auf die ausgewählten Cloud-Plattformen zu instanziieren. Durch die Verwendung der Graph-Pipeline kann auf Veränderungen schnell reagiert werden, z.B. auf das Austauschen und Hinzufügen von Services, einen Wechsel der unterlagerten Cloud-Plattform oder Ausfällen von Services. Dazu überwacht die Graph-Pipeline die vom Benutzer erstellte Servicekomposition und führt die zuvor beschriebenen Schritte automatisiert durch. Somit ist es möglich, zur Laufzeit Services an- und abzubestellen.

Service Use Cases
Innerhalb des Forschungsprojektes wurden verschiede Use Cases für Services unterschiedlicher Anforderungen hinsichtlich der benötigten Daten (Menge, Verfügbarkeit), Laufzeiteigenschaften und Verarbeitungszeit nach Eintritt der Ereignisse definiert. Ein im Projekt umgesetzter Service dient der Analyse von Material und Lieferanten auf Qualitätsmerkmale. Er agiert auf verschiedenen Datenquellen und hat als Ziel, die Verbesserung der Produktqualität durch eine bessere Überwachung zu gewährleisten. Hierbei ist die zu verarbeitende Datenmenge sehr groß, jedoch spielt der Zeitpunkt der Verarbeitung keine Rolle, da die Analyseergebnisse nicht direkt in den Produktionsprozess eingespielt werden. Zusätzlich zur genannten Services-Gruppe wurden Services identifiziert, die nicht nur viele Quellen ansprechen und große Datenmengen verarbeiten müssen, sondern die Analyseergebnisse auch zu einem bestimmten Zeitpunkt bereitstellen müssen. Beispielhaft für diese Anforderung ist ein Service im Bereich von Predictive Control. Hier werden Daten aus Maschinen und Anlagen erhoben und zunächst eine Modellentwicklung auf historischen Daten durchgeführt. Dieses Modell dient als Prozessabbild. Im nächsten Schritt werden Steuerungseinstellungen sowie Messdaten herangezogen, um Prognosen anhand des erarbeiteten Modelles für jede beliebige Steuerungseinstellung zu generieren. Unter Berücksichtigung der Beschränkungen wird die bestmögliche Prognose bzw. Konfiguration hinsichtlich eines definierten Ziels an die Steuerung weitergegeben. Vor allem der letzte Schritt erfordert eine Durchführung im Steuerungstakt im ms-Bereich.
Model Predictive Control
Model Predictive Control (MPC) als Methode meint die Steuerung eines Prozesses, z.B. in einer Produktionsmaschine, die automatisch und selbstlernend auf Veränderungen an den Parametern reagiert. Die Ziele können vielfältig sein: Zumeist ist es die Sicherstellung eines stabilen Prozesses und damit die Vermeidung von Störungen und Fehlern. Am konkreten Beispiel eines Produktionsprozesses geht es beispielsweise um die Vermeidung von Stillständen, reduzierte Rüstzeiten oder eingehaltene Qualitätsstandards. Diese automatisch optimierte Prozesskontrolle ist erst durch die Digitalisierung der Maschinendaten im Zusammenhang der heutigen Möglichkeiten der Datenspeicherung und -verarbeitung möglich geworden. Allgemein sind für die Anwendung von MPC drei Bestandteile notwendig: das dynamische Model, die historischen Daten und eine Kostenfunktion für den gleitenden Prognosehorizont. Das dynamische Model beschreibt die Zustände des Prozesses, der bei physikalischen Prozessen in der Regel von einer Familie an Differenzialgleichungen abgebildet wird. Da das Aufstellen einer Differenzialgleichung sehr zeitintensiv und aufwändig sein kann, werden mittlerweile auch Verfahren des Maschinellen Lernens benutzt, um aus historischen Daten die Zustände des Prozesses schnell zu bewerten. Die Qualität der Ergebnisse ist dabei ähnlich, dauert aber deutlich kürzer und ist weniger komplex. Für datenbasiertes MPC können nur Methoden des Maschinellen Lernens benutzt werden, die auch eine Interpretation ermöglichen, wie z.B. Regression oder Bäume. Wenn die Zustände des Prozesses beschrieben werden können, kann man sich dem Hauptproblem des Predictive Control zuwenden und definiert dazu einen zeitabhängigen optimalen Zustand. Ziel ist es, unter Berücksichtigung der Kostenfunktion, den Verlauf des Prozesses so nah wie möglich an dem optimalen Zustand zu halten. Oft sind spezielle Nebenbedingungen für die Optimierung notwendig, um sicherzustellen, dass die vorgeschlagene Lösung auch in der Praxis umgesetzt werden kann. Einschränkungen können z.B. für bestimmte Temperaturparameter gelten, da diese bei zu hohen Temperaturen zu irreparablen Schäden an anderen Bauteilen führen. Diese Nebenbedingungen sind für jede Aufgabe individuell festzulegen, was sehr aufwändig sein kann.
Open- oder closed-loop
Die Anpassung basiert entweder nur auf den Anfangswerten des Prozesses und der Steuerungsinputs, was man open-loop nennt, oder mit einem Feedback des Outputs, closed-loop genannt. Im zweiten Fall wird zwar weit in die Zukunft prognostiziert, es wird aber nur die aktuellste Steuerungsanweisung in die Praxis umgesetzt. Danach wird in einem rollierenden Verfahren in Abhängigkeit der tatsächlichen Qualität bzw. des Feedbacks die Optimierung neu berechnet und wiederum nur der aktuellste Wert verwendet. Open-loops sind leicht zu implementieren, stabil und ergeben immer die gewünschte Lösung, funktionieren jedoch nur in geschlossenen, nicht dynamischen Systemen und können daher nur selten in der Praxis angewendet werden. Closed-loops können durch die Berücksichtigung des Outputs in der Optimierung den vorgegebenen Zustand auch dann erreichen, wenn das System nicht geschlossen ist, d.h. wenn es nicht geplante Änderungen geben kann. Allerdings sind die Ergebnisse dann nicht zwingend global, sondern nur lokal optimal. Die Feedbackoptimierung ist allgemein allerdings sehr komplex und schwierig zu implementieren: So kann es zu Stabilitätsproblemen kommen, die zu Konvergenzschwierigkeiten führen. Die Aufstellung und Implementierung eines geeigneten Algorithmus und Modelles ist daher meist sehr zeitaufwändig und damit kostenintensiv. Um die Stabilität und Konvergenz besser im Griff zu haben, werden in der Industrie allgemein nur lineare oder quadratische Zielfunktionen verwendet, die zusammen mit den Nebenbedingungen ein konvexes Optimierungsmodell ergeben. Bei konvexen Modellen ist jedes lokale Optimum gleichzeitig ein globales. Somit reicht es hier aus, im Lösungsprozess nur nach lokalen Optima zu suchen. Wenn man die Verbindung zwischen dem Zustand des Prozesses und Steuerungsinputs parametrisieren kann, lässt sich zeigen, dass das Optimierungsproblem immer eine Lösung hat und zu dieser Lösung konvergiert. Besonders geeignet für die Anwendung von MPC sind Prozesse, bei denen der Zeitversatz zwischen Steuerungsparametern und dem Output (Qualitätsmessung) sehr hoch ist, es eine starke Interaktion zwischen Steuerungsparametern und Qualität gibt oder die Nebenbedingungen für die Steuerung sehr wichtig sind.
SPS-MAGAZIN 9/2017: Im Jahr nach Picasso
SPS-MAGAZIN 10/2017: Die Macht der Datenanalyse
SPS-MAGAZIN 11/2017: Was kann TSN beitragen?
Stuttgarter Innovationstage 2018
Der revolutionäre Ansatz von Steuerungen aus der Cloud stand oft in Konflikt mit konservativen IT-Vorgaben und stellte daher Partner mit großen IT-Infrastrukturen vor organisatorische Hürden. Um einen engen Austausch über verschiedene Fachbereiche hinweg zu fördern veranstaltet das ISW der Universität Stuttgart zum zweiten Mal die ‚Stuttgarter Innovationstage – Steuerungstechnik aus der Cloud‘. Mit Vorträgen aus den Fachbereichen klassische Automatisierungstechnik und IT sowie juristischen und mathematischen Aspekten können Teilnehmer am 30. und 31. Januar 2018 in Stuttgart einen ersten Schritt zum interdisziplinären Wissensaustausch machen.