Deep Vision – CNN auf FPGAs
Neuronale Netze lösen komplexe Bildverarbeitung
Da für viele typische Vision-Anwendungen kleine neuronale Netze ausreichen, lassen sich Prozessoren wie FPGAs auch für Convolutional Neural Networks (CNNs) wirkungsvoll nutzen. Dadurch sind hohe Durchsatzraten und auch der Einsatz in Embedded Vision Systemen möglich.
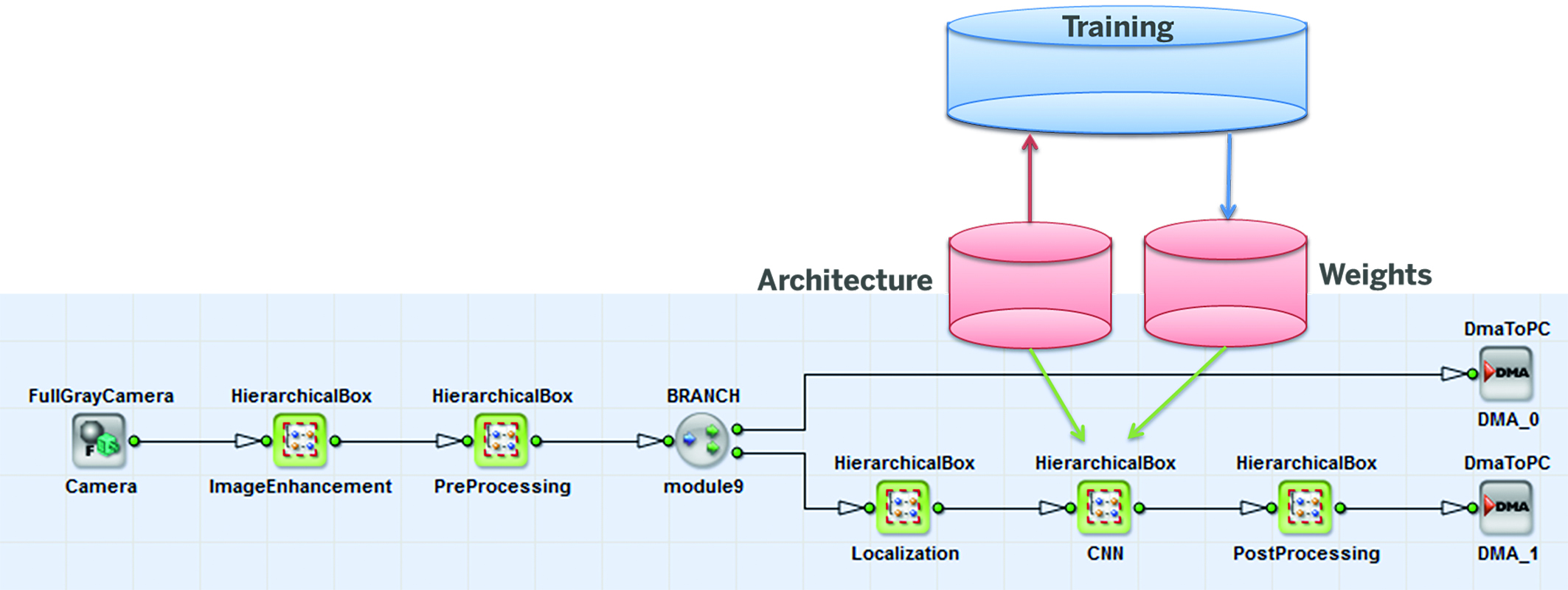
Bild 1 | Für die Nutzung von CNNs auf FPGA-Hardwareplattformen kann die grafische
Entwicklungsumgebung VisualApplets eingesetzt werden. (Bild: Silicon Software GmbH)
Klassische Bildverarbeitungs-Applikationen stoßen an ihre Grenzen, wenn Prüfobjekte deformiert sind und irreguläre Formen bzw. große Objektvariationen aufweisen, die Beleuchtungssituation ungeeignet ist oder eine Linsenverzerrung vorliegt. Lassen sich die Rahmenbedingungen für die Bilderfassung nicht kontrollieren, sind individuelle Algorithmen zur Merkmalsbeschreibung kaum möglich. CNNs hingegen definieren Merkmale über die Trainingsmethode, ohne mathematische Modelle. Damit ist prinzipiell eine Bilderfassung und -analyse in schwierigen Situationen wie bei reflektierenden Oberflächen, sich bewegenden Objekten, Gesichtserkennung oder im Robotik-Umfeld möglich, aber auch eine einfachere Klassifizierung von Bilddaten direkt von der Vorverarbeitung zum Klassifizierungsergebnis. Dennoch können CNNs nicht alle Bereiche der klassischen Bildverarbeitung, z.B. eine genaue Positionsbestimmung von Objekten, abdecken. Hier müssen erweiterte, neuartige CNNs entwickelt werden.
Optimierte CNNs beschleunigen Vision
Praktische Erfahrungswerte mit CNNs haben zu mathematischen Annahmen und Vereinfachungen (Pooling, ReLu und Vermeidung von Overfitting) sowie zu einer Reduktion des Berechnungsaufwands geführt, was die Umsetzung tieferer Netzwerke ermöglichte. Durch die Erkenntnis, die Bildtiefe bei gleichbleibender Erkennungsrate zu reduzieren, und durch Optimierungen in der Algorithmik lassen sich CNNs beschleunigen. CNNs sind verschiebungs- und teilweise skalierungsinvariant und ermöglichen es, gleiche Netzstrukturen für unterschiedliche Bildauflösungen einzusetzen. Für viele Bildverarbeitungsaufgaben sind bereits kleinere neuronale Netze oftmals ausreichend. Aufgrund des hohen Maßes an Parallelverarbeitung lassen sich diese besonders gut auf FPGAs einsetzen, auf denen CNNs auch hoch aufgelöste Bilddaten in Echtzeit analysieren und klassifizieren. FPGAs gelten als Beschleuniger von Bildverarbeitungsaufgaben und Garant für Echtzeitprozesse mit deterministischen Latenzen. Bisher standen der hohe Programmieraufwand und die verhältnismäßig geringen bereitstehenden Ressourcen in einem FPGA einer effizienten Nutzung im Weg. Die algorithmischen Vereinfachungen ermöglichen es, effiziente Netze mit hohen Durchsatzraten in einem FPGA aufzubauen.

Bild 2 | Detektierte Fehlerklassen (von li. nach re.: Einwalzungen, Flecken, Risse, Körner, Einschlüsse, Kratzer), [http://faculty.neu.edu.cn/yunhyan/NEU_surface_defect_database.html] (Bild: NEU Surface Defect Database)
Neuer CNN-Operator
Für die Nutzung von CNNs auf FPGA-Hardwareplattformen kann die grafische Entwicklungsumgebung VisualApplets eingesetzt werden. Ein CNN-Operator ermöglicht Anwendern, vielfältige Anwendungsdesigns ohne Hardware-Programmierung in kurzer Zeit zu erstellen und synthetisieren. Mit der Übergabe der im Trainingsprozess ermittelten Parameter für die Gewichte und Gradienten an den CNN-Operator, wird das Design an die spezielle Anwendungsaufgabe konfiguriert. Der Operator lässt sich in ein Flussdiagramm-Design mit digitalen Kameraquellen als Bild-Input und weiteren Bildverarbeitungsoperatoren zur Optimierung der Bildvorverarbeitung kombinieren. Für den Einsatz besonders großer neuronaler Netze für komplexe CNN-Anwendungen wird ein programmierbarer Framegrabber der Microenable Marathon Reihe veröffentlicht, der mit 2,5x größeren FPGA-Ressourcen – verglichen mit dem aktuellen Flaggschiff der Marathon Reihe – und voraussichtlich mehr als 1GB/s CNN-Bearbeitungsbandbreite für neuronale Netze prädestiniert ist. Lauffähig sind die CNNs nicht nur auf FPGAs von Framegrabbern, sondern auch auf VisualApplets kompatiblen Kameras und Vision-Sensoren. Da FPGAs im Vergleich mit GPUs bis zu zehnmal energieeffizienter sind, lassen sich CNN-basierte Anwendungen gerade auch auf Embedded-Systemen oder mobilen Robotern mit der notwendigen geringen Wärmeleistung besonders gut realisieren. Künftig wird sich zudem die Anwendungsvielfalt und -komplexität mit neuronalen Netzen aufgrund neu entwickelter Spezialprozessoren weiter erhöhen. Bei der Entwicklung neuer Hard- und Softwarelösungen und für den Austausch von Forschungsergebnissen besteht eine Kooperation mit dem Institut für Industrielle Informationstechnik (IIIT) am Karlsruher Institut für Technologie (KIT) im Rahmen des Projektes ‚FPGA-based Machine Learning for industrial applications‘. Zur Ermittlung des Prozentsatzes richtig erkannter Defekte bei schwierigen Umgebungsbedingungen wie etwa reflektierenden metallischen Oberflächen wurde ein neuronales Netz mit 1.800 Bildern antrainiert, auf denen sechs verschiedenartige Defektklassen vorhanden waren. Große Unterschiede bei Kratzern bei gleichzeitig geringen Unterschieden bei der Rissbildung gepaart mit verschiedenen Grautönen der Oberfläche durch Beleuchtungs- und Materialänderungen machten die Analyse der Oberfläche für herkömmliche Bildverarbeitungssysteme fast unmöglich. Die Auswertung ergab, dass die verschiedenen Defekte durch das neuronale Netz durchschnittlich zu 97,4% sicher klassifiziert wurden, was ein höherer Wert verglichen mit klassischen Methoden ist. Der Datendurchsatz in diesem Anwendungsaufbau lag bei 400MB/s. Im Vergleich hierzu erreichte eine CPU-basierte Softwarelösung durchschnittlich 20MB/s.
Ausblick
Anforderungen, dass CNN-Verfahren deterministisch und algorithmisch verifizierbar sein müssen, werden den Einzug in die Bildverarbeitung erschweren. Ebenso sind Dokumentationsmöglichkeiten, welcher Bereich als Fehler erkannt wurde, sowie dessen Segmentierung und Speicherung, heute noch nicht implementiert. Bisher sind Training und operativer Einsatz von CNNs zwei getrennte Prozesse. Neue Generationen von FPGAs mit höheren Ressourcen oder mit Nutzung von leistungsfähigen ARM/CPU- und GPU-Kernen werden aber in Zukunft ein on-the-fly Training auf dem gerade aufgenommenen Bildmaterial ermöglichen, was Erkennungsraten weiter steigen lässt und Lernprozesse deutlich vereinfacht.